A better way to evaluate training programs
In nearly every organisation I have worked in, there is a ritual that occurs that will be familiar to many of you. A training program (or course) ends. An email goes out. Learners click a star rating, answer a few questions about whether they enjoyed it and whether they’d recommend it to a colleague, and then get on with their day. The L&D team collects the responses, averages the scores, and files them away as proof that learning happened.
It didn’t. Or rather, it might have. We genuinely don’t know. And that’s the problem.
We’ve been measuring the wrong things
The Kirkpatrick model has been the dominant framework for training evaluation for over six decades. It has been translated, adapted, and cited so many times that it has the status of received wisdom in most L&D functions. Reaction, Learning, Behaviour, Results. Most practitioners could recite those levels in their sleep.
But the model has a structural flaw that we don’t talk about nearly enough: it bundles everything that happens in a training room into a single, undifferentiated category called “Learning.” Under Kirkpatrick, measuring whether someone can recite a list of compliance terminology and measuring whether they can make sound judgements in complex, ambiguous workplace scenarios count as the same thing. They are not the same thing. Not even close.
The consequence is that “Level 2 Learning” assessments in the wild tend to drift toward whatever is easiest to measure. And what’s easiest to measure is usually knowledge recall — multiple choice questions, terminology checks, end-of-module quizzes — assessed immediately after the learning event, while everything is still fresh. This tells us almost nothing meaningful. A learner can pass a knowledge check on the day and remember nothing a week later. Passing a quiz doesn’t mean they can make better decisions. It certainly doesn’t mean they can perform differently in their job.
And yet this is what most organisations use to validate the effectiveness of their learning investment.
The learning survey problem is worse than you think
If measuring knowledge recall is a limited proxy for learning, measuring learner satisfaction points you in the wrong direction entirely. And yet reaction surveys (typically issued at the end of a course or program) remain the most commonly used evaluation instrument in the profession.
The research on this is damning. Learner satisfaction is not correlated with learning outcomes. Learners tend to like courses that are passive, easy, and comfortable — think long explanatory videos, clean slides, a presenter who doesn’t challenge them too hard. They tend to dislike courses that are cognitively demanding — the ones with realistic scenarios, delayed testing, and the productive struggle that actually drives retention. If we optimise our training programs for high satisfaction scores, we are optimising away from learning effectiveness.
Dr Will Thalheimer, whose work on evaluation I have enormous respect for, puts this clearly in his research: traditional satisfaction surveys that measure learner happiness or whether someone would recommend a course to a colleague are “inadequate to validate learning success.” They’re measuring something, certainly. Just not the thing we care about.
When an L&D function uses learning surveys as its primary evidence of effectiveness, it is not demonstrating the value of learning. It is demonstrating that learners didn’t hate it. Those are very different claims.
A better way to think about evaluation
Thalheimer’s Learning-Transfer Evaluation Model (LTEM) offers a more honest map of what evaluation can and cannot tell us. Rather than four broad levels, it proposes eight tiers — and it’s explicit about which measurement approaches are adequate and which are not.
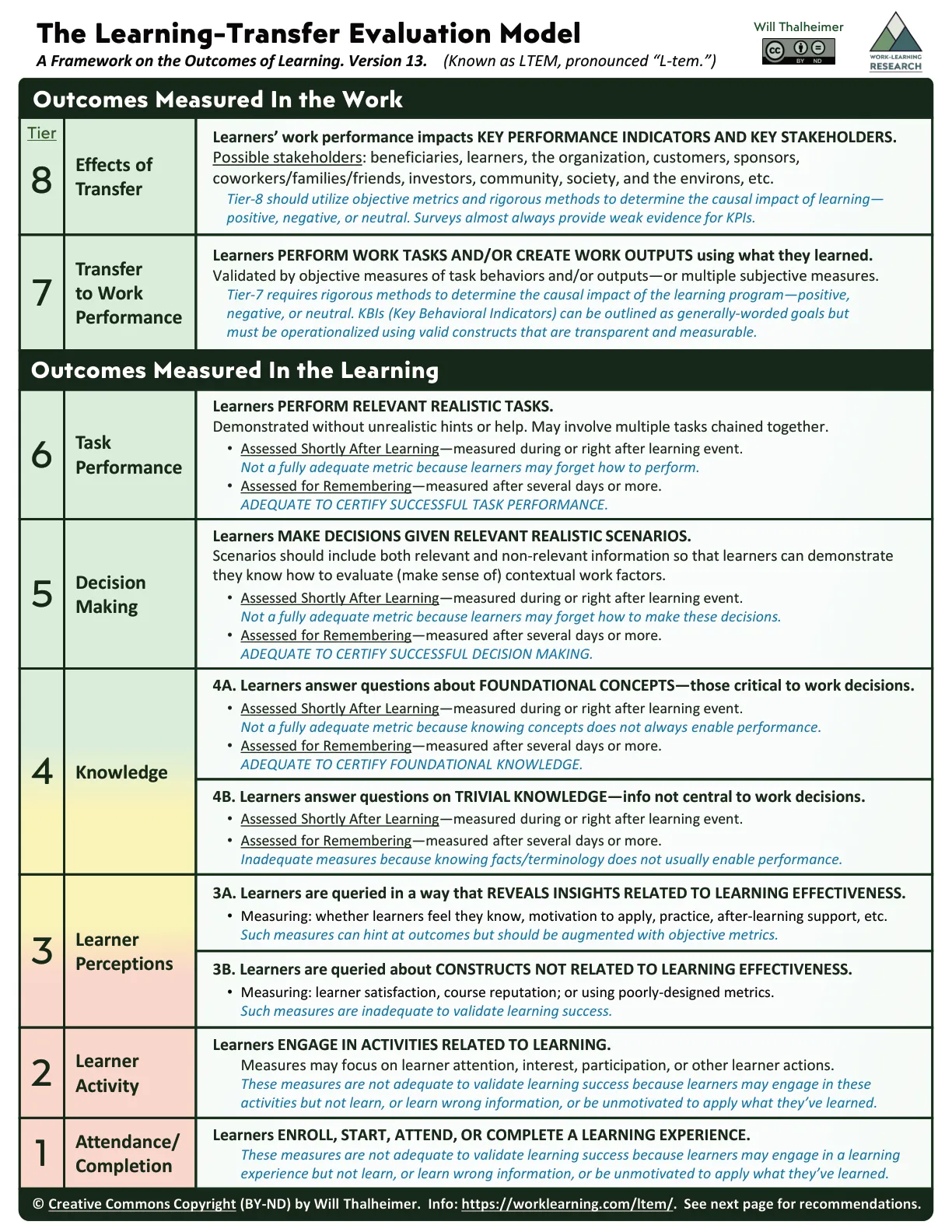
The lower tiers — attendance, completion rates, learner engagement, and basic satisfaction surveys — are marked as inadequate for validating learning. They may be useful for formative purposes, understanding what’s happening in the room, but they don’t tell us whether learning occurred. Many L&D functions are working almost entirely in this space.
The more meaningful territory begins at Tier 4, where we start measuring whether learners have gained the foundational knowledge that enables workplace decision-making — not trivial facts, but the conceptual understanding that actually drives performance. Above that, Tiers 5 and 6 ask whether learners can make sound decisions in realistic scenarios, and whether they can perform relevant tasks without unrealistic scaffolding — ideally tested after a delay, to account for forgetting. Only then, at Tiers 7 and 8, do we get to transfer and impact: did behaviour change in the workplace, and did that change produce meaningful results?
The value of this framework goes beyond identifying better measurement targets. It shifts the conversation about what we’re designing for. If we know we want to measure decision-making quality, we’d better make sure the learning experience gives people practice making decisions. Evaluation and design become linked in a way they rarely are when the only question at the end is “did you enjoy this?”
The honest reckoning
Measuring transfer and impact is not easy. Tiers 7 and 8 require rigorous methods, time, and organisational access that many L&D functions simply don’t have. Thalheimer acknowledges this clearly — LTEM is not a call to measure everything, nor to always chase the highest tiers. It’s a call to be honest about what the data we’re collecting actually tells us, and to prioritise measurement that connects to genuine capability change.
That honesty is what the profession needs more of. We have spent decades defending our seat at the table on the basis of metrics that don’t hold up to scrutiny. When a business leader asks whether the training worked and we hand them a 4.2 out of 5 satisfaction rating, we are not answering their question. We are deflecting it.
The better answer — the one that builds genuine credibility — starts with a different question: Can the people we trained do something meaningfully different as a result? Not did they complete it. Not did they like it. Not could they recall it on the day. Can they perform better in the contexts that matter?
Getting to that answer is harder. It requires more rigour upfront, more courage in stakeholder conversations, and a willingness to sit with uncertainty when the evidence is messy. But it’s the only version of evaluation that earns the profession the influence it wants.
This is the first in a series of articles on the structural challenges facing the L&D profession. If you’re interested in Thalheimer’s LTEM framework, the full model and supporting report are available at worklearning.com/ltem.